![]()
[2025] Databricks-Generative-AI-Engineer-Associate Answers Databricks-Generative-AI-Engineer-Associate Free Demo Are Based On The Real Exam
Databricks-Generative-AI-Engineer-Associate [Apr-2025 Newly Released] Exam Questions For You To Pass
Databricks Databricks-Generative-AI-Engineer-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
NEW QUESTION # 12
A Generative Al Engineer is creating an LLM system that will retrieve news articles from the year 1918 and related to a user's query and summarize them. The engineer has noticed that the summaries are generated well but often also include an explanation of how the summary was generated, which is undesirable.
Which change could the Generative Al Engineer perform to mitigate this issue?
- A. Provide few shot examples of desired output format to the system and/or user prompt.
- B. Revisit their document ingestion logic, ensuring that the news articles are being ingested properly.
- C. Tune the chunk size of news articles or experiment with different embedding models.
- D. Split the LLM output by newline characters to truncate away the summarization explanation.
Answer: A
Explanation:
To mitigate the issue of the LLM including explanations of how summaries are generated in its output, the best approach is to adjust the training or prompt structure. Here's why Option D is effective:
* Few-shot Learning: By providing specific examples of how the desired output should look (i.e., just the summary without explanation), the model learns the preferred format. This few-shot learning approach helps the model understand not only what content to generate but also how to format its responses.
* Prompt Engineering: Adjusting the user prompt to specify the desired output format clearly can guide the LLM to produce summaries without additional explanatory text. Effective prompt design is crucial in controlling the behavior of generative models.
Why Other Options Are Less Suitable:
* A: While technically feasible, splitting the output by newline and truncating could lead to loss of important content or create awkward breaks in the summary.
* B: Tuning chunk sizes or changing embedding models does not directly address the issue of the model's tendency to generate explanations along with summaries.
* C: Revisiting document ingestion logic ensures accurate source data but does not influence how the model formats its output.
By using few-shot examples and refining the prompt, the engineer directly influences the output format, making this approach the most targeted and effective solution.
NEW QUESTION # 13
A Generative AI Engineer is designing an LLM-powered live sports commentary platform. The platform provides real-time updates and LLM-generated analyses for any users who would like to have live summaries, rather than reading a series of potentially outdated news articles.
Which tool below will give the platform access to real-time data for generating game analyses based on the latest game scores?
- A. Foundation Model APIs
- B. AutoML
- C. DatabrickslQ
- D. Feature Serving
Answer: D
Explanation:
* Problem Context: The engineer is developing an LLM-powered live sports commentary platform that needs to provide real-time updates and analyses based on the latest game scores. The critical requirement here is the capability to access and integrate real-time data efficiently with the platform for immediate analysis and reporting.
* Explanation of Options:
* Option A: DatabricksIQ: While DatabricksIQ offers integration and data processing capabilities, it is more aligned with data analytics rather than real-time feature serving, which is crucial for immediate updates necessary in a live sports commentary context.
* Option B: Foundation Model APIs: These APIs facilitate interactions with pre-trained models and could be part of the solution, but on their own, they do not provide mechanisms to access real- time game scores.
* Option C: Feature Serving: This is the correct answer as feature serving specifically refers to the real-time provision of data (features) to models for prediction. This would be essential for an LLM that generates analyses based on live game data, ensuring that the commentary is current and based on the latest events in the sport.
* Option D: AutoML: This tool automates the process of applying machine learning models to real-world problems, but it does not directly provide real-time data access, which is a critical requirement for the platform.
Thus,Option C(Feature Serving) is the most suitable tool for the platform as it directly supports the real-time data needs of an LLM-powered sports commentary system, ensuring that the analyses and updates are based on the latest available information.
NEW QUESTION # 14
A Generative Al Engineer is building a RAG application that answers questions about internal documents for the company SnoPen AI.
The source documents may contain a significant amount of irrelevant content, such as advertisements, sports news, or entertainment news, or content about other companies.
Which approach is advisable when building a RAG application to achieve this goal of filtering irrelevant information?
- A. Include in the system prompt that the application is not supposed to answer any questions unrelated to SnoPen Al.
- B. Keep all articles because the RAG application needs to understand non-company content to avoid answering questions about them.
- C. Include in the system prompt that any information it sees will be about SnoPenAI, even if no data filtering is performed.
- D. Consolidate all SnoPen AI related documents into a single chunk in the vector database.
Answer: A
Explanation:
In a Retrieval-Augmented Generation (RAG) application built to answer questions about internal documents, especially when the dataset contains irrelevant content, it's crucial to guide the system to focus on the right information. The best way to achieve this is byincluding a clear instruction in the system prompt(option C).
* System Prompt as Guidance:The system prompt is an effective way to instruct the LLM to limit its focus to SnoPen AI-related content. By clearly specifying that the model should avoid answering questions unrelated to SnoPen AI, you add an additional layer of control that helps the model stay on- topic, even if irrelevant content is present in the dataset.
* Why This Approach Works:The prompt acts as a guiding principle for the model, narrowing its focus to specific domains. This prevents the model from generating answers based on irrelevant content, such as advertisements or news unrelated to SnoPen AI.
* Why Other Options Are Less Suitable:
* A (Keep All Articles): Retaining all content, including irrelevant materials, without any filtering makes the system prone to generating answers based on unwanted data.
* B (Include in the System Prompt about SnoPen AI): This option doesn't address irrelevant content directly, and without filtering, the model might still retrieve and use irrelevant data.
* D (Consolidating Documents into a Single Chunk): Grouping documents into a single chunk makes the retrieval process less efficient and won't help filter out irrelevant content effectively.
Therefore, instructing the system in the prompt not to answer questions unrelated to SnoPen AI (option C) is the best approach to ensure the system filters out irrelevant information.
NEW QUESTION # 15
A Generative Al Engineer has already trained an LLM on Databricks and it is now ready to be deployed.
Which of the following steps correctly outlines the easiest process for deploying a model on Databricks?
- A. Log the model as a pickle object, upload the object to Unity Catalog Volume, register it to Unity Catalog using MLflow, and start a serving endpoint
- B. Save the model along with its dependencies in a local directory, build the Docker image, and run the Docker container
- C. Log the model using MLflow during training, directly register the model to Unity Catalog using the MLflow API, and start a serving endpoint
- D. Wrap the LLM's prediction function into a Flask application and serve using Gunicorn
Answer: C
Explanation:
* Problem Context: The goal is to deploy a trained LLM on Databricks in the simplest and most integrated manner.
* Explanation of Options:
* Option A: This method involves unnecessary steps like logging the model as a pickle object, which is not the most efficient path in a Databricks environment.
* Option B: Logging the model with MLflow during training and then using MLflow's API to register and start serving the model is straightforward and leverages Databricks' built-in functionalities for seamless model deployment.
* Option C: Building and running a Docker container is a complex and less integrated approach within the Databricks ecosystem.
* Option D: Using Flask and Gunicorn is a more manual approach and less integrated compared to the native capabilities of Databricks and MLflow.
OptionBprovides the most straightforward and efficient process, utilizing Databricks' ecosystem to its full advantage for deploying models.
NEW QUESTION # 16
A Generative Al Engineer has developed an LLM application to answer questions about internal company policies. The Generative AI Engineer must ensure that the application doesn't hallucinate or leak confidential data.
Which approach should NOT be used to mitigate hallucination or confidential data leakage?
- A. Limit the data available based on the user's access level
- B. Fine-tune the model on your data, hoping it will learn what is appropriate and not
- C. Use a strong system prompt to ensure the model aligns with your needs.
- D. Add guardrails to filter outputs from the LLM before it is shown to the user
Answer: B
Explanation:
When addressing concerns of hallucination and data leakage in an LLM application for internal company policies, fine-tuning the model on internal data with the hope it learns data boundaries can be problematic:
* Risk of Data Leakage: Fine-tuning on sensitive or confidential data does not guarantee that the model will not inadvertently include or reference this data in its outputs. There's a risk of overfitting to the specific data details, which might lead to unintended leakage.
* Hallucination: Fine-tuning does not necessarily mitigate the model's tendency to hallucinate; in fact, it might exacerbate it if the training data is not comprehensive or representative of all potential queries.
Better Approaches:
* A,C, andDinvolve setting up operational safeguards and constraints that directly address data leakage and ensure responses are aligned with specific user needs and security levels.
Fine-tuning lacks the targeted control needed for such sensitive applications and can introduce new risks, making it an unsuitable approach in this context.
NEW QUESTION # 17
A Generative AI Engineer wants to build an LLM-based solution to help a restaurant improve its online customer experience with bookings by automatically handling common customer inquiries. The goal of the solution is to minimize escalations to human intervention and phone calls while maintaining a personalized interaction. To design the solution, the Generative AI Engineer needs to define the input data to the LLM and the task it should perform.
Which input/output pair will support their goal?
- A. Input: Customer reviews; Output: Classify review sentiment
- B. Input: Online chat logs; Output: Group the chat logs by users, followed by summarizing each user's interactions
- C. Input: Online chat logs; Output: Buttons that represent choices for booking details
- D. Input: Online chat logs; Output: Cancellation options
Answer: C
Explanation:
Context: The goal is to improve the online customer experience in a restaurant by handling common inquiries about bookings, minimizing escalations, and maintaining personalized interactions.
Explanation of Options:
* Option A: Grouping and summarizing chat logs by user could provide insights into customer interactions but does not directly address the task of handling booking inquiries or minimizing escalations.
* Option B: Using chat logs to generate interactive buttons for booking details directly supports the goal of facilitating online bookings, minimizing the need for human intervention by providing clear, interactive options for customers to self-serve.
* Option C: Classifying sentiment of customer reviews does not directly help with booking inquiries, although it might provide valuable feedback insights.
* Option D: Providing cancellation options is helpful but narrowly focuses on one aspect of the booking process and doesn't support the broader goal of handling common inquiries about bookings.
Option Bbest supports the goal of improving online interactions by using chat logs to generate actionable items for customers, helping them complete booking tasks efficiently and reducing the need for human intervention.
NEW QUESTION # 18
When developing an LLM application, it's crucial to ensure that the data used for training the model complies with licensing requirements to avoid legal risks.
Which action is NOT appropriate to avoid legal risks?
- A. Reach out to the data curators directly before you have started using the trained model to let them know.
- B. Reach out to the data curators directly after you have started using the trained model to let them know.
- C. Use any available data you personally created which is completely original and you can decide what license to use.
- D. Only use data explicitly labeled with an open license and ensure the license terms are followed.
Answer: B
Explanation:
* Problem Context: When using data to train a model, it's essential to ensure compliance with licensing to avoid legal risks. Legal issues can arise from using data without permission, especially when it comes from third-party sources.
* Explanation of Options:
* Option A: Reaching out to data curatorsbeforeusing the data is an appropriate action. This allows you to ensure you have permission or understand the licensing terms before starting to use the data in your model.
* Option B: Usingoriginal datathat you personally created is always a safe option. Since you have full ownership over the data, there are no legal risks, as you control the licensing.
* Option C: Using data that is explicitly labeled with an open license and adhering to the license terms is a correct and recommended approach. This ensures compliance with legal requirements.
* Option D: Reaching out to the data curatorsafteryou have already started using the trained model isnot appropriate. If you've already used the data without understanding its licensing terms, you may have already violated the terms of use, which could lead to legal complications. It's essential to clarify the licensing termsbeforeusing the data, not after.
Thus,Option Dis not appropriate because it could expose you to legal risks by using the data without first obtaining the proper licensing permissions.
NEW QUESTION # 19
A Generative Al Engineer is tasked with improving the RAG quality by addressing its inflammatory outputs.
Which action would be most effective in mitigating the problem of offensive text outputs?
- A. Curate upstream data properly that includes manual review before it is fed into the RAG system
- B. Inform the user of the expected RAG behavior
- C. Increase the frequency of upstream data updates
- D. Restrict access to the data sources to a limited number of users
Answer: A
Explanation:
Addressing offensive or inflammatory outputs in a Retrieval-Augmented Generation (RAG) system is critical for improving user experience and ensuring ethical AI deployment. Here's whyDis the most effective approach:
* Manual data curation: The root cause of offensive outputs often comes from the underlying data used to train the model or populate the retrieval system. By manually curating the upstream data and conducting thorough reviews before the data is fed into the RAG system, the engineer can filter out harmful, offensive, or inappropriate content.
* Improving data quality: Curating data ensures the system retrieves and generates responses from a high-quality, well-vetted dataset. This directly impacts the relevance and appropriateness of the outputs from the RAG system, preventing inflammatory content from being included in responses.
* Effectiveness: This strategy directly tackles the problem at its source (the data) rather than just mitigating the consequences (such as informing users or restricting access). It ensures that the system consistently provides non-offensive, relevant information.
Other options, such as increasing the frequency of data updates or informing users about behavior expectations, may not directly mitigate the generation of inflammatory outputs.
NEW QUESTION # 20
A company has a typical RAG-enabled, customer-facing chatbot on its website.
Select the correct sequence of components a user's questions will go through before the final output is returned. Use the diagram above for reference.
- A. 1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model
- B. 1.context-augmented prompt, 2.vector search, 3.embedding model, 4.response-generating LLM
- C. 1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
- D. 1.embedding model, 2.vector search, 3.context-augmented prompt, 4.response-generating LLM
Answer: D
Explanation:
To understand how a typical RAG-enabled customer-facing chatbot processes a user's question, let's go through the correct sequence as depicted in the diagram and explained in option A:
* Embedding Model (1):The first step involves the user's question being processed through an embedding model. This model converts the text into a vector format that numerically represents the text. This step is essential for allowing the subsequent vector search to operate effectively.
* Vector Search (2):The vectors generated by the embedding model are then used in a vector search mechanism. This search identifies the most relevant documents or previously answered questions that are stored in a vector format in a database.
* Context-Augmented Prompt (3):The information retrieved from the vector search is used to create a context-augmented prompt. This step involves enhancing the basic user query with additional relevant information gathered to ensure the generated response is as accurate and informative as possible.
* Response-Generating LLM (4):Finally, the context-augmented prompt is fed into a response- generating large language model (LLM). This LLM uses the prompt to generate a coherent and contextually appropriate answer, which is then delivered as the final output to the user.
Why Other Options Are Less Suitable:
* B, C, D: These options suggest incorrect sequences that do not align with how a RAG system typically processes queries. They misplace the role of embedding models, vector search, and response generation in an order that would not facilitate effective information retrieval and response generation.
Thus, the correct sequence isembedding model, vector search, context-augmented prompt, response- generating LLM, which is option A.
NEW QUESTION # 21
A Generative Al Engineer is tasked with developing a RAG application that will help a small internal group of experts at their company answer specific questions, augmented by an internal knowledge base. They want the best possible quality in the answers, and neither latency nor throughput is a huge concern given that the user group is small and they're willing to wait for the best answer. The topics are sensitive in nature and the data is highly confidential and so, due to regulatory requirements, none of the information is allowed to be transmitted to third parties.
Which model meets all the Generative Al Engineer's needs in this situation?
- A. OpenAI GPT-4
- B. BGE-large
- C. Llama2-70B
- D. Dolly 1.5B
Answer: B
Explanation:
Problem Context: The Generative AI Engineer needs a model for a Retrieval-Augmented Generation (RAG) application that provides high-quality answers, where latency and throughput are not major concerns. The key factors areconfidentialityandsensitivityof the data, as well as the requirement for all processing to be confined to internal resources without external data transmission.
Explanation of Options:
* Option A: Dolly 1.5B: This model does not typically support RAG applications as it's more focused on image generation tasks.
* Option B: OpenAI GPT-4: While GPT-4 is powerful for generating responses, its standard deployment involves cloud-based processing, which could violate the confidentiality requirements due to external data transmission.
* Option C: BGE-large: The BGE (Big Green Engine) large model is a suitable choice if it is configured to operate on-premises or within a secure internal environment that meets regulatory requirements.
Assuming this setup, BGE-large can provide high-quality answers while ensuring that data is not transmitted to third parties, thus aligning with the project's sensitivity and confidentiality needs.
* Option D: Llama2-70B: Similar to GPT-4, unless specifically set up for on-premises use, it generally relies on cloud-based services, which might risk confidential data exposure.
Given the sensitivity and confidentiality concerns,BGE-largeis assumed to be configurable for secure internal use, making it the optimal choice for this scenario.
NEW QUESTION # 22
A team wants to serve a code generation model as an assistant for their software developers. It should support multiple programming languages. Quality is the primary objective.
Which of the Databricks Foundation Model APIs, or models available in the Marketplace, would be the best fit?
- A. BGE-large
- B. Llama2-70b
- C. CodeLlama-34B
- D. MPT-7b
Answer: C
Explanation:
For a code generation model that supports multiple programming languages and where quality is the primary objective,CodeLlama-34Bis the most suitable choice. Here's the reasoning:
* Specialization in Code Generation:CodeLlama-34B is specifically designed for code generation tasks.
This model has been trained with a focus on understanding and generating code, which makes it particularly adept at handling various programming languages and coding contexts.
* Capacity and Performance:The "34B" indicates a model size of 34 billion parameters, suggesting a high capacity for handling complex tasks and generating high-quality outputs. The large model size typically correlates with better understanding and generation capabilities in diverse scenarios.
* Suitability for Development Teams:Given that the model is optimized for code, it will be able to assist software developers more effectively than general-purpose models. It understands coding syntax, semantics, and the nuances of different programming languages.
* Why Other Options Are Less Suitable:
* A (Llama2-70b): While also a large model, it's more general-purpose and may not be as fine- tuned for code generation as CodeLlama.
* B (BGE-large): This model may not specifically focus on code generation.
* C (MPT-7b): Smaller than CodeLlama-34B and likely less capable in handling complex code generation tasks at high quality.
Therefore, for a high-quality, multi-language code generation application,CodeLlama-34B(option D) is the best fit.
NEW QUESTION # 23
A Generative Al Engineer would like an LLM to generate formatted JSON from emails. This will require parsing and extracting the following information: order ID, date, and sender email. Here's a sample email: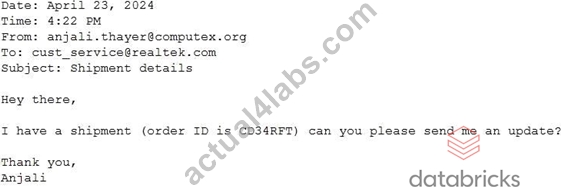
They will need to write a prompt that will extract the relevant information in JSON format with the highest level of output accuracy.
Which prompt will do that?
- A. You will receive customer emails and need to extract date, sender email, and order ID. You should return the date, sender email, and order ID information in JSON format.
- B. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Here's an example: {"date": "April 16, 2024", "sender_email": "[email protected]", "order_id":
"RE987D"} - C. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
- D. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
Answer: B
Explanation:
Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM' s responses.
Explanation of Options:
* Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
* Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
* Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
* Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore,Option Bis optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
NEW QUESTION # 24
A Generative Al Engineer is building a system which will answer questions on latest stock news articles.
Which will NOT help with ensuring the outputs are relevant to financial news?
- A. Implement a comprehensive guardrail framework that includes policies for content filters tailored to the finance sector.
- B. Incorporate manual reviews to correct any problematic outputs prior to sending to the users
- C. Increase the compute to improve processing speed of questions to allow greater relevancy analysis C Implement a profanity filter to screen out offensive language
Answer: C
Explanation:
In the context of ensuring that outputs are relevant to financial news, increasing compute power (option B) does not directly improve therelevanceof the LLM-generated outputs. Here's why:
* Compute Power and Relevancy:Increasing compute power can help the model process inputs faster, but it does not inherentlyimprove therelevanceof the answers. Relevancy depends on the data sources, the retrieval method, and the filtering mechanisms in place, not on how quickly the model processes the query.
* What Actually Helps with Relevance:Other methods, like content filtering, guardrails, or manual review, can directly impact the relevance of the model's responses by ensuring the model focuses on pertinent financial content. These methods help tailor the LLM's responses to the financial domain and avoid irrelevant or harmful outputs.
* Why Other Options Are More Relevant:
* A (Comprehensive Guardrail Framework): This will ensure that the model avoids generating content that is irrelevant or inappropriate in the finance sector.
* C (Profanity Filter): While not directly related to financial relevancy, ensuring the output is clean and professional is still important in maintaining the quality of responses.
* D (Manual Review): Incorporating human oversight to catch and correct issues with the LLM's output ensures the final answers are aligned with financial content expectations.
Thus, increasing compute power does not help with ensuring the outputs are more relevant to financial news, making option B the correct answer.
NEW QUESTION # 25
A Generative AI Engineer received the following business requirements for an external chatbot.
The chatbot needs to know what types of questions the user asks and routes to appropriate models to answer the questions. For example, the user might ask about upcoming event details. Another user might ask about purchasing tickets for a particular event.
What is an ideal workflow for such a chatbot?
- A. The chatbot should only look at previous event information
- B. The chatbot should only process payments
- C. There should be two different chatbots handling different types of user queries.
- D. The chatbot should be implemented as a multi-step LLM workflow. First, identify the type of question asked, then route the question to the appropriate model. If it's an upcoming event question, send the query to a text-to-SQL model. If it's about ticket purchasing, the customer should be redirected to a payment platform.
Answer: D
Explanation:
* Problem Context: The chatbot must handle various types of queries and intelligently route them to the appropriate responses or systems.
* Explanation of Options:
* Option A: Limiting the chatbot to only previous event information restricts its utility and does not meet the broader business requirements.
* Option B: Having two separate chatbots could unnecessarily complicate user interaction and increase maintenance overhead.
* Option C: Implementing a multi-step workflow where the chatbot first identifies the type of question and then routes it accordingly is the most efficient and scalable solution. This approach allows the chatbot to handle a variety of queries dynamically, improving user experience and operational efficiency.
* Option D: Focusing solely on payments would not satisfy all the specified user interaction needs, such as inquiring about event details.
Option Coffers a comprehensive workflow that maximizes the chatbot's utility and responsiveness to different user needs, aligning perfectly with the business requirements.
NEW QUESTION # 26
A Generative AI Engineer is building a RAG application that will rely on context retrieved from source documents that are currently in PDF format. These PDFs can contain both text and images. They want to develop a solution using the least amount of lines of code.
Which Python package should be used to extract the text from the source documents?
- A. unstructured
- B. beautifulsoup
- C. flask
- D. numpy
Answer: A
Explanation:
* Problem Context: The engineer needs to extract text from PDF documents, which may contain both text and images. The goal is to find a Python package that simplifies this task using the least amount of code.
* Explanation of Options:
* Option A: flask: Flask is a web framework for Python, not suitable for processing or extracting content from PDFs.
* Option B: beautifulsoup: Beautiful Soup is designed for parsing HTML and XML documents, not PDFs.
* Option C: unstructured: This Python package is specifically designed to work with unstructured data, including extracting text from PDFs. It provides functionalities to handle various types of content in documents with minimal coding, making it ideal for the task.
* Option D: numpy: Numpy is a powerful library for numerical computing in Python and does not provide any tools for text extraction from PDFs.
Given the requirement,Option C(unstructured) is the most appropriate as it directly addresses the need to efficiently extract text from PDF documents with minimal code.
NEW QUESTION # 27
A Generative AI Engineer developed an LLM application using the provisioned throughput Foundation Model API. Now that the application is ready to be deployed, they realize their volume of requests are not sufficiently high enough to create their own provisioned throughput endpoint. They want to choose a strategy that ensures the best cost-effectiveness for their application.
What strategy should the Generative AI Engineer use?
- A. Change to a model with a fewer number of parameters in order to reduce hardware constraint issues
- B. Deploy the model using pay-per-token throughput as it comes with cost guarantees
- C. Switch to using External Models instead
- D. Throttle the incoming batch of requests manually to avoid rate limiting issues
Answer: B
Explanation:
* Problem Context: The engineer needs a cost-effective deployment strategy for an LLM application with relatively low request volume.
* Explanation of Options:
* Option A: Switching to external models may not provide the required control or integration necessary for specific application needs.
* Option B: Using a pay-per-token model is cost-effective, especially for applications with variable or low request volumes, as it aligns costs directly with usage.
* Option C: Changing to a model with fewer parameters could reduce costs, but might also impact the performance and capabilities of the application.
* Option D: Manually throttling requests is a less efficient and potentially error-prone strategy for managing costs.
OptionBis ideal, offering flexibility and cost control, aligning expenses directly with the application's usage patterns.
NEW QUESTION # 28
A Generative Al Engineer is responsible for developing a chatbot to enable their company's internal HelpDesk Call Center team to more quickly find related tickets and provide resolution. While creating the GenAI application work breakdown tasks for this project, they realize they need to start planning which data sources (either Unity Catalog volume or Delta table) they could choose for this application. They have collected several candidate data sources for consideration:
call_rep_history: a Delta table with primary keys representative_id, call_id. This table is maintained to calculate representatives' call resolution from fields call_duration and call start_time.
transcript Volume: a Unity Catalog Volume of all recordings as a *.wav files, but also a text transcript as *.txt files.
call_cust_history: a Delta table with primary keys customer_id, cal1_id. This table is maintained to calculate how much internal customers use the HelpDesk to make sure that the charge back model is consistent with actual service use.
call_detail: a Delta table that includes a snapshot of all call details updated hourly. It includes root_cause and resolution fields, but those fields may be empty for calls that are still active.
maintenance_schedule - a Delta table that includes a listing of both HelpDesk application outages as well as planned upcoming maintenance downtimes.
They need sources that could add context to best identify ticket root cause and resolution.
Which TWO sources do that? (Choose two.)
- A. call_cust_history
- B. maintenance_schedule
- C. call_rep_history
- D. transcript Volume
- E. call_detail
Answer: D,E
Explanation:
In the context of developing a chatbot for a company's internal HelpDesk Call Center, the key is to select data sources that provide the most contextual and detailed information about the issues being addressed. This includes identifying the root cause and suggesting resolutions. The two most appropriate sources from the list are:
* Call Detail (Option D):
* Contents: This Delta table includes a snapshot of all call details updated hourly, featuring essential fields like root_cause and resolution.
* Relevance: The inclusion of root_cause and resolution fields makes this source particularly valuable, as it directly contains the information necessary to understand and resolve the issues discussed in the calls. Even if some records are incomplete, the data provided is crucial for a chatbot aimed at speeding up resolution identification.
* Transcript Volume (Option E):
* Contents: This Unity Catalog Volume contains recordings in .wav format and text transcripts in .txt files.
* Relevance: The text transcripts of call recordings can provide in-depth context that the chatbot can analyze to understand the nuances of each issue. The chatbot can use natural language processing techniques to extract themes, identify problems, and suggest resolutions based on previous similar interactions documented in the transcripts.
Why Other Options Are Less Suitable:
* A (Call Cust History): While it provides insights into customer interactions with the HelpDesk, it focuses more on the usage metrics rather than the content of the calls or the issues discussed.
* B (Maintenance Schedule): This data is useful for understanding when services may not be available but does not contribute directly to resolving user issues or identifying root causes.
* C (Call Rep History): Though it offers data on call durations and start times, which could help in assessing performance, it lacks direct information on the issues being resolved.
Therefore, Call Detail and Transcript Volume are the most relevant data sources for a chatbot designed to assist with identifying and resolving issues in a HelpDesk Call Center setting, as they provide direct and contextual information related to customer issues.
NEW QUESTION # 29
A Generative AI Engineer has been asked to build an LLM-based question-answering application. The application should take into account new documents that are frequently published. The engineer wants to build this application with the least cost and least development effort and have it operate at the lowest cost possible.
Which combination of chaining components and configuration meets these requirements?
- A. For the application a prompt, an agent and a fine-tuned LLM are required. The agent is used by the LLM to retrieve relevant content that is inserted into the prompt which is given to the LLM to generate answers.
- B. For the application a prompt, a retriever, and an LLM are required. The retriever output is inserted into the prompt which is given to the LLM to generate answers.
- C. For the question-answering application, prompt engineering and an LLM are required to generate answers.
- D. The LLM needs to be frequently with the new documents in order to provide most up-to-date answers.
Answer: B
Explanation:
Problem Context: The task is to build an LLM-based question-answering application that integrates new documents frequently with minimal costs and development efforts.
Explanation of Options:
* Option A: Utilizes a prompt and a retriever, with the retriever output being fed into the LLM. This setup is efficient because it dynamically updates the data pool via the retriever, allowing the LLM to provide up-to-date answers based on the latest documents without needing tofrequently retrain the model. This method offers a balance of cost-effectiveness and functionality.
* Option B: Requires frequent retraining of the LLM, which is costly and labor-intensive.
* Option C: Only involves prompt engineering and an LLM, which may not adequately handle the requirement for incorporating new documents unless it's part of an ongoing retraining or updating mechanism, which would increase costs.
* Option D: Involves an agent and a fine-tuned LLM, which could be overkill and lead to higher development and operational costs.
Option Ais the most suitable as it provides a cost-effective, minimal development approach while ensuring the application remains up-to-date with new information.
NEW QUESTION # 30
What is an effective method to preprocess prompts using custom code before sending them to an LLM?
- A. Write a MLflow PyFunc model that has a separate function to process the prompts
- B. Directly modify the LLM's internal architecture to include preprocessing steps
- C. It is better not to introduce custom code to preprocess prompts as the LLM has not been trained with examples of the preprocessed prompts
- D. Rather than preprocessing prompts, it's more effective to postprocess the LLM outputs to align the outputs to desired outcomes
Answer: A
Explanation:
The most effective way to preprocess prompts using custom code is to write a custom model, such as an MLflow PyFunc model. Here's a breakdown of why this is the correct approach:
* MLflow PyFunc Models:MLflow is a widely used platform for managing the machine learning lifecycle, including experimentation, reproducibility, and deployment. APyFuncmodel is a generic Python function model that can implement custom logic, which includes preprocessing prompts.
* Preprocessing Prompts:Preprocessing could include various tasks like cleaning up the user input, formatting it according to specific rules, or augmenting it with additional context before passing it to the LLM. Writing this preprocessing as part of a PyFunc model allows the custom code to be managed, tested, and deployed easily.
* Modular and Reusable:By separating the preprocessing logic into a PyFunc model, the system becomes modular, making it easier to maintain and update without needing to modify the core LLM or retrain it.
* Why Other Options Are Less Suitable:
* A (Modify LLM's Internal Architecture): Directly modifying the LLM's architecture is highly impractical and can disrupt the model's performance. LLMs are typically treated as black-box models for tasks like prompt processing.
* B (Avoid Custom Code): While it's true that LLMs haven't been explicitly trained with preprocessed prompts, preprocessing can still improve clarity and alignment with desired input formats without confusing the model.
* C (Postprocessing Outputs): While postprocessing the output can be useful, it doesn't address the need for clean and well-formatted inputs, which directly affect the quality of the model's responses.
Thus, using an MLflow PyFunc model allows for flexible and controlled preprocessing of prompts in a scalable way, making it the most effective method.
NEW QUESTION # 31
......
New 2025 Realistic Free Databricks Databricks-Generative-AI-Engineer-Associate Exam Dump Questions and Answer: https://simplilearn.actual4labs.com/Databricks/Databricks-Generative-AI-Engineer-Associate-actual-exam-dumps.html